Java 혹은 Scala로 람다를 작성시 Serializable Exception 이 자주 발생한다.
컴파일이 아닌, 런타임에러가 발생하므로,,, 도통 원인을 모르겠다.
하나하나 따져보자.
보통 자바 웹개발을 하는 사람은 Serializable을 볼 일이 거의 없다.
네트워크 소켓통신으로 객체를 주고받는 경우가 없기 때문이다.(직렬화)
보통 하는 일이 객체를 JSON 이나 XML로 변경하는 정도??
그래서 더욱... Serializable Exception이 낯설다.
1. 성공케이스
package org.mystudy.testcase;
import java.util.Arrays;
import org.apache.log4j.PropertyConfigurator;
import org.apache.spark.api.java.JavaRDD;
import org.apache.spark.api.java.JavaSparkContext;
public class TestCase1 {
JavaSparkContext sc = null;
private TestCase1() {
PropertyConfigurator.configure("D:\\workspace\\spark\\learning.spark\\src\\resources\\log4j.properties");
sc = new JavaSparkContext("local[2]", "First Spark App");
}
public static void main(String... strings) {
TestCase1 t = new TestCase1();
t.proc1();
t.proc2();
}
private void proc1() {
JavaRDD rdd2 = sc.parallelize(Arrays.asList(1, 2, 3, 4));
JavaRDD rdd3 = rdd2.map(a -> a + 1);
System.out.println(rdd3.collect());
}
private void proc2() {
JavaRDD rdd2 = sc.parallelize(Arrays.asList(1, 2, 3, 4));
int num2 = 3;
JavaRDD rdd3 = rdd2.map(a -> a + num2);
System.out.println(rdd3.collect());
}
}
좋은 케이스 : 에러 없이 잘... 작동한다.
JAVA8의 람다식이다.
2. 실패사례 - 전역변수(멤버필드)
package org.mystudy.testcase;
import java.util.Arrays;
import org.apache.log4j.PropertyConfigurator;
import org.apache.spark.api.java.JavaRDD;
import org.apache.spark.api.java.JavaSparkContext;
public class TestCase2 {
private int num1 = 4;
JavaSparkContext sc = null;
private TestCase2() {
PropertyConfigurator.configure("D:\\workspace\\spark\\learning.spark\\src\\resources\\log4j.properties");
sc = new JavaSparkContext("local[2]", "First Spark App");
}
public static void main(String... strings) {
TestCase2 t = new TestCase2();
System.out.println("t:"+t);
t.proc3();
}
private void proc3() {
JavaRDD rdd2 = sc.parallelize(Arrays.asList(1, 2, 3, 4));
JavaRDD rdd3 = rdd2.map(a -> a + this.num1); // Exception 발생
System.out.println(rdd3.collect());
}
}
Exception 발생
람다식에 this.num1 이 사용되었다. this는 TestCase2 자체를 의미하므로, 현재 TestCase2 가 Serializable 을 구현하지 않았으므로 아래와 같은 Exception 이 발생한다.
2-1 해결책
package org.mystudy.testcase;
import java.util.Arrays;
import org.apache.log4j.PropertyConfigurator;
import org.apache.spark.api.java.JavaRDD;
import org.apache.spark.api.java.JavaSparkContext;
public class TestCase2Sol1 {
private int num1 = 4;
JavaSparkContext sc = null;
private TestCase2Sol1() {
PropertyConfigurator.configure("D:\\workspace\\spark\\learning.spark\\src\\resources\\log4j.properties");
sc = new JavaSparkContext("local[2]", "First Spark App");
}
public static void main(String... strings) {
TestCase2Sol1 t = new TestCase2Sol1();
t.proc3();
}
private void proc3() {
JavaRDD rdd2 = sc.parallelize(Arrays.asList(1, 2, 3, 4));
int num1 = this.num1; // 해결
JavaRDD rdd3 = rdd2.map(a -> a + num1); // 해결
System.out.println(rdd3.collect());
}
}
[러닝 스파크] 책에서 소개하는 방식으로...
this.num1의 값을 지역변수로 재할당해서 사용하면 된다.
2-2 이렇게도 해결할 수 있을까? 안돼~
package org.mystudy.testcase;
import java.io.Serializable;
import java.util.Arrays;
import org.apache.log4j.PropertyConfigurator;
import org.apache.spark.api.java.JavaRDD;
import org.apache.spark.api.java.JavaSparkContext;
public class TestCase2Sol2 implements Serializable {
private int num1 = 4;
private JavaSparkContext sc = null;
private TestCase2Sol2() {
PropertyConfigurator.configure("D:\\workspace\\spark\\learning.spark\\src\\resources\\log4j.properties");
sc = new JavaSparkContext("local[2]", "First Spark App");
}
public static void main(String... strings) {
TestCase2Sol2 t = new TestCase2Sol2();
System.out.println("t:"+t);
System.out.println("sc:"+t.sc);
t.proc3();
}
private void proc3() {
JavaRDD rdd2 = sc.parallelize(Arrays.asList(1, 2, 3, 4));
JavaRDD rdd3 = rdd2.map(a -> a + this.num1); // 여전히 Exception 발생
System.out.println(rdd3.collect());
}
}
implements Serializable 을 했음에도 Exception이 발생한다.
이유인즉은, JavaSparkContext 객체를 위 코드에서 클래스의 전역변수로 사용하고 있는데, 아무리 클래스에 Serializable을 구현해놓아도
멤버필드 즉, JavaSparkContext sc 는 기본적으로 직렬화가 안되는 모양이다;;;
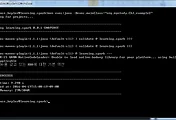
16/04/08 00:10:33 WARN NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
t:org.mystudy.testcase.TestCase2Sol2@247667dd
sc:org.apache.spark.api.java.JavaSparkContext@6f099cef
Exception in thread "main" org.apache.spark.SparkException: Task not serializable
at org.apache.spark.util.ClosureCleaner$.ensureSerializable(ClosureCleaner.scala:304)
at org.apache.spark.util.ClosureCleaner$.org$apache$spark$util$ClosureCleaner$$clean(ClosureCleaner.scala:294)
at org.apache.spark.util.ClosureCleaner$.clean(ClosureCleaner.scala:122)
at org.apache.spark.SparkContext.clean(SparkContext.scala:2055)
at org.apache.spark.rdd.RDD$$anonfun$map$1.apply(RDD.scala:324)
at org.apache.spark.rdd.RDD$$anonfun$map$1.apply(RDD.scala:323)
at org.apache.spark.rdd.RDDOperationScope$.withScope(RDDOperationScope.scala:150)
at org.apache.spark.rdd.RDDOperationScope$.withScope(RDDOperationScope.scala:111)
at org.apache.spark.rdd.RDD.withScope(RDD.scala:316)
at org.apache.spark.rdd.RDD.map(RDD.scala:323)
at org.apache.spark.api.java.JavaRDDLike$class.map(JavaRDDLike.scala:96)
at org.apache.spark.api.java.AbstractJavaRDDLike.map(JavaRDDLike.scala:46)
at org.mystudy.testcase.TestCase2Sol2.proc3(TestCase2Sol2.java:28)
at org.mystudy.testcase.TestCase2Sol2.main(TestCase2Sol2.java:23)
Caused by: java.io.NotSerializableException: org.apache.spark.api.java.JavaSparkContext
Serialization stack:
- object not serializable (class: org.apache.spark.api.java.JavaSparkContext, value: org.apache.spark.api.java.JavaSparkContext@6f099cef)
- field (class: org.mystudy.testcase.TestCase2Sol2, name: sc, type: class org.apache.spark.api.java.JavaSparkContext)
- object (class org.mystudy.testcase.TestCase2Sol2, org.mystudy.testcase.TestCase2Sol2@247667dd)
- element of array (index: 0)
- array (class [Ljava.lang.Object;, size 1)
- field (class: java.lang.invoke.SerializedLambda, name: capturedArgs, type: class [Ljava.lang.Object;)
- object (class java.lang.invoke.SerializedLambda, SerializedLambda[capturingClass=class org.mystudy.testcase.TestCase2Sol2, functionalInterfaceMethod=org/apache/spark/api/java/function/Function.call:(Ljava/lang/Object;)Ljava/lang/Object;, implementation=invokeSpecial org/mystudy/testcase/TestCase2Sol2.lambda$0:(Ljava/lang/Integer;)Ljava/lang/Integer;, instantiatedMethodType=(Ljava/lang/Integer;)Ljava/lang/Integer;, numCaptured=1])
- writeReplace data (class: java.lang.invoke.SerializedLambda)
- object (class org.mystudy.testcase.TestCase2Sol2$$Lambda$4/1353512285, org.mystudy.testcase.TestCase2Sol2$$Lambda$4/1353512285@116a2108)
- field (class: org.apache.spark.api.java.JavaPairRDD$$anonfun$toScalaFunction$1, name: fun$1, type: interface org.apache.spark.api.java.function.Function)
- object (class org.apache.spark.api.java.JavaPairRDD$$anonfun$toScalaFunction$1, <function1>)
at org.apache.spark.serializer.SerializationDebugger$.improveException(SerializationDebugger.scala:40)
at org.apache.spark.serializer.JavaSerializationStream.writeObject(JavaSerializer.scala:47)
at org.apache.spark.serializer.JavaSerializerInstance.serialize(JavaSerializer.scala:101)
at org.apache.spark.util.ClosureCleaner$.ensureSerializable(ClosureCleaner.scala:301)
... 13 more
2-3 이렇게 해결할 수 있다.
package org.mystudy.testcase;
import java.io.Serializable;
import java.util.Arrays;
import org.apache.log4j.PropertyConfigurator;
import org.apache.spark.api.java.JavaRDD;
import org.apache.spark.api.java.JavaSparkContext;
public class TestCase2Sol3 implements Serializable {
private int num1 = 4;
private TestCase2Sol3() {
}
public static void main(String... strings) {
TestCase2Sol3 t = new TestCase2Sol3();
t.proc3();
}
private void proc3() {
PropertyConfigurator.configure("D:\\workspace\\spark\\learning.spark\\src\\resources\\log4j.properties");
JavaSparkContext sc = new JavaSparkContext("local[2]", "First Spark App");
JavaRDD rdd2 = sc.parallelize(Arrays.asList(1, 2, 3, 4));
JavaRDD rdd3 = rdd2.map(a -> a + this.num1); // 해결
System.out.println(rdd3.collect());
}
}
JavaSparkContext 를 지역변수로 사용하였다. 해결됨.
3.실패사례 - 함수사용(멤버메서드)
package org.mystudy.testcase;
import java.util.Arrays;
import org.apache.log4j.PropertyConfigurator;
import org.apache.spark.api.java.JavaRDD;
import org.apache.spark.api.java.JavaSparkContext;
public class TestCase3 {
private TestCase3() {
PropertyConfigurator.configure("D:\\workspace\\spark\\learning.spark\\src\\resources\\log4j.properties");
}
public static void main(String... strings) {
TestCase3 t = new TestCase3();
System.out.println("t:"+t);
t.proc3();
}
private int add(int num) {
return num + 1;
}
private void proc3() {
JavaSparkContext sc = new JavaSparkContext("local[2]", "First Spark App");
JavaRDD rdd2 = sc.parallelize(Arrays.asList(1, 2, 3, 4));
JavaRDD rdd3 = rdd2.map(a -> add(a)); // Exception 발생
System.out.println(rdd3.collect());
}
}
this 를 사용했던 경우와 같은 문제이다. TestCase3 클래스를 Serializable 하지 않아서 생긴 문제이다.
t:org.mystudy.testcase.TestCase3@75a1cd57
16/04/08 00:17:32 WARN NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
Exception in thread "main" org.apache.spark.SparkException: Task not serializable
at org.apache.spark.util.ClosureCleaner$.ensureSerializable(ClosureCleaner.scala:304)
at org.apache.spark.util.ClosureCleaner$.org$apache$spark$util$ClosureCleaner$$clean(ClosureCleaner.scala:294)
at org.apache.spark.util.ClosureCleaner$.clean(ClosureCleaner.scala:122)
at org.apache.spark.SparkContext.clean(SparkContext.scala:2055)
at org.apache.spark.rdd.RDD$$anonfun$map$1.apply(RDD.scala:324)
at org.apache.spark.rdd.RDD$$anonfun$map$1.apply(RDD.scala:323)
at org.apache.spark.rdd.RDDOperationScope$.withScope(RDDOperationScope.scala:150)
at org.apache.spark.rdd.RDDOperationScope$.withScope(RDDOperationScope.scala:111)
at org.apache.spark.rdd.RDD.withScope(RDD.scala:316)
at org.apache.spark.rdd.RDD.map(RDD.scala:323)
at org.apache.spark.api.java.JavaRDDLike$class.map(JavaRDDLike.scala:96)
at org.apache.spark.api.java.AbstractJavaRDDLike.map(JavaRDDLike.scala:46)
at org.mystudy.testcase.TestCase3.proc3(TestCase3.java:26)
at org.mystudy.testcase.TestCase3.main(TestCase3.java:18)
Caused by: java.io.NotSerializableException: org.mystudy.testcase.TestCase3
Serialization stack:
- object not serializable (class: org.mystudy.testcase.TestCase3, value: org.mystudy.testcase.TestCase3@75a1cd57)
- element of array (index: 0)
- array (class [Ljava.lang.Object;, size 1)
- field (class: java.lang.invoke.SerializedLambda, name: capturedArgs, type: class [Ljava.lang.Object;)
- object (class java.lang.invoke.SerializedLambda, SerializedLambda[capturingClass=class org.mystudy.testcase.TestCase3, functionalInterfaceMethod=org/apache/spark/api/java/function/Function.call:(Ljava/lang/Object;)Ljava/lang/Object;, implementation=invokeSpecial org/mystudy/testcase/TestCase3.lambda$0:(Ljava/lang/Integer;)Ljava/lang/Integer;, instantiatedMethodType=(Ljava/lang/Integer;)Ljava/lang/Integer;, numCaptured=1])
- writeReplace data (class: java.lang.invoke.SerializedLambda)
- object (class org.mystudy.testcase.TestCase3$$Lambda$4/503353142, org.mystudy.testcase.TestCase3$$Lambda$4/503353142@7a1f8def)
- field (class: org.apache.spark.api.java.JavaPairRDD$$anonfun$toScalaFunction$1, name: fun$1, type: interface org.apache.spark.api.java.function.Function)
- object (class org.apache.spark.api.java.JavaPairRDD$$anonfun$toScalaFunction$1, <function1>)
at org.apache.spark.serializer.SerializationDebugger$.improveException(SerializationDebugger.scala:40)
at org.apache.spark.serializer.JavaSerializationStream.writeObject(JavaSerializer.scala:47)
at org.apache.spark.serializer.JavaSerializerInstance.serialize(JavaSerializer.scala:101)
at org.apache.spark.util.ClosureCleaner$.ensureSerializable(ClosureCleaner.scala:301)
... 13 more
3-1 해결
package org.mystudy.testcase;
import java.io.Serializable;
import java.util.Arrays;
import org.apache.log4j.PropertyConfigurator;
import org.apache.spark.api.java.JavaRDD;
import org.apache.spark.api.java.JavaSparkContext;
public class TestCase3Sol1 implements Serializable {
private TestCase3Sol1() {
PropertyConfigurator.configure("D:\\workspace\\spark\\learning.spark\\src\\resources\\log4j.properties");
}
public static void main(String... strings) {
TestCase3Sol1 t = new TestCase3Sol1();
t.proc3();
}
private int add(int num) {
return num + 1;
}
private void proc3() {
JavaSparkContext sc = new JavaSparkContext("local[2]", "First Spark App");
JavaRDD rdd2 = sc.parallelize(Arrays.asList(1, 2, 3, 4));
JavaRDD rdd3 = rdd2.map(a -> add(a)); // 해결
System.out.println(rdd3.collect());
}
}
Serializable 구현해서 해결하였다.
4.실패사례 - Function 등 인터페이스 문제
package org.mystudy.testcase;
import java.util.Arrays;
import org.apache.log4j.PropertyConfigurator;
import org.apache.spark.api.java.JavaRDD;
import org.apache.spark.api.java.JavaSparkContext;
import org.apache.spark.api.java.function.Function;
public class TestCase4 {
private TestCase4() {
PropertyConfigurator.configure("D:\\workspace\\spark\\learning.spark\\src\\resources\\log4j.properties");
}
public static void main(String... strings) {
TestCase4 t = new TestCase4();
System.out.println("t:"+t);
t.proc3();
}
private void proc3() {
class AAA implements Function<Integer, Integer> {
@Override
public Integer call(Integer v1) throws Exception {
return v1 + 1;
}
}
JavaSparkContext sc = new JavaSparkContext("local[2]", "First Spark App");
JavaRDD<Integer> rdd2 = sc.parallelize(Arrays.asList(1, 2, 3, 4));
JavaRDD<Integer> rdd3 = rdd2.map(new AAA()); // Exception
System.out.println(rdd3.collect());
}
}
무엇이 문제일까?
내부클래스를 사용했더니... 그 내부클래스를 품고 있는 바깥클래스 즉, TestCase4의 Serializable 여부를 묻고 있다.
아무리 Function 인터페이스가 Serializable을 구현했다고 해도... 그 Function 을 구현한 AAA 라는 클래스가 바깥클래스의 정체성과 연관이 있나보다.
어쩌면 AAA 라는 내부클래스를 정의할때 org.mystudy.testcase.TestCase4$1AAA@60acd609 이렇게 사용하기에.... TestCase4$1, 결국 TestCase4 가 결정적인 역할을 하는 것 같다.
앞의 예제 this.num1 과 같이... 실제 전달하는 값은 num1 이지만, 결국 스파크에 전달되는 것은 num1을 포함하는 this가 전달되는 것과 마찬가지로..
스파크에 AAA만 전달되는 것 같지만 결국은 AAA를 포함하는 TestCase4 가 전달되는 것은 아닌가 싶다. 그래서 TestCase4 의 Serializable 여부를 묻고 있는 것이 아닌가???
t:org.mystudy.testcase.TestCase4@5e91993f
16/04/08 00:24:03 WARN NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
Exception in thread "main" org.apache.spark.SparkException: Task not serializable
at org.apache.spark.util.ClosureCleaner$.ensureSerializable(ClosureCleaner.scala:304)
at org.apache.spark.util.ClosureCleaner$.org$apache$spark$util$ClosureCleaner$$clean(ClosureCleaner.scala:294)
at org.apache.spark.util.ClosureCleaner$.clean(ClosureCleaner.scala:122)
at org.apache.spark.SparkContext.clean(SparkContext.scala:2055)
at org.apache.spark.rdd.RDD$$anonfun$map$1.apply(RDD.scala:324)
at org.apache.spark.rdd.RDD$$anonfun$map$1.apply(RDD.scala:323)
at org.apache.spark.rdd.RDDOperationScope$.withScope(RDDOperationScope.scala:150)
at org.apache.spark.rdd.RDDOperationScope$.withScope(RDDOperationScope.scala:111)
at org.apache.spark.rdd.RDD.withScope(RDD.scala:316)
at org.apache.spark.rdd.RDD.map(RDD.scala:323)
at org.apache.spark.api.java.JavaRDDLike$class.map(JavaRDDLike.scala:96)
at org.apache.spark.api.java.AbstractJavaRDDLike.map(JavaRDDLike.scala:46)
at org.mystudy.testcase.TestCase4.proc3(TestCase4.java:31)
at org.mystudy.testcase.TestCase4.main(TestCase4.java:19)
Caused by: java.io.NotSerializableException: org.mystudy.testcase.TestCase4
Serialization stack:
- object not serializable (class: org.mystudy.testcase.TestCase4, value: org.mystudy.testcase.TestCase4@5e91993f)
- field (class: org.mystudy.testcase.TestCase4$1AAA, name: this$0, type: class org.mystudy.testcase.TestCase4)
- object (class org.mystudy.testcase.TestCase4$1AAA, org.mystudy.testcase.TestCase4$1AAA@60acd609)
- field (class: org.apache.spark.api.java.JavaPairRDD$$anonfun$toScalaFunction$1, name: fun$1, type: interface org.apache.spark.api.java.function.Function)
- object (class org.apache.spark.api.java.JavaPairRDD$$anonfun$toScalaFunction$1, <function1>)
at org.apache.spark.serializer.SerializationDebugger$.improveException(SerializationDebugger.scala:40)
at org.apache.spark.serializer.JavaSerializationStream.writeObject(JavaSerializer.scala:47)
at org.apache.spark.serializer.JavaSerializerInstance.serialize(JavaSerializer.scala:101)
at org.apache.spark.util.ClosureCleaner$.ensureSerializable(ClosureCleaner.scala:301)
... 13 more
4-1. 혹시나 이렇게 해보았지만...
package org.mystudy.testcase;
import java.util.Arrays;
import org.apache.log4j.PropertyConfigurator;
import org.apache.spark.api.java.JavaRDD;
import org.apache.spark.api.java.JavaSparkContext;
import org.apache.spark.api.java.function.Function;
public class TestCase4Sol1 {
private TestCase4Sol1() {
PropertyConfigurator.configure("D:\\workspace\\spark\\learning.spark\\src\\resources\\log4j.properties");
}
public static void main(String... strings) {
TestCase4Sol1 t = new TestCase4Sol1();
System.out.println("t:"+t);
t.proc3();
}
class AAA implements Function<Integer, Integer> {
@Override
public Integer call(Integer v1) throws Exception {
return v1 + 1;
}
}
private void proc3() {
JavaSparkContext sc = new JavaSparkContext("local[2]", "First Spark App");
JavaRDD<Integer> rdd2 = sc.parallelize(Arrays.asList(1, 2, 3, 4));
JavaRDD<Integer> rdd3 = rdd2.map(new AAA()); //Exception
System.out.println(rdd3.collect());
}
}
혹시나 class를 함수밖으로 빼보았지만.... 동일한 Exception이 발생한다.
t:org.mystudy.testcase.TestCase4Sol1@5e91993f
16/04/08 00:33:11 WARN NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
Exception in thread "main" org.apache.spark.SparkException: Task not serializable
at org.apache.spark.util.ClosureCleaner$.ensureSerializable(ClosureCleaner.scala:304)
at org.apache.spark.util.ClosureCleaner$.org$apache$spark$util$ClosureCleaner$$clean(ClosureCleaner.scala:294)
at org.apache.spark.util.ClosureCleaner$.clean(ClosureCleaner.scala:122)
at org.apache.spark.SparkContext.clean(SparkContext.scala:2055)
at org.apache.spark.rdd.RDD$$anonfun$map$1.apply(RDD.scala:324)
at org.apache.spark.rdd.RDD$$anonfun$map$1.apply(RDD.scala:323)
at org.apache.spark.rdd.RDDOperationScope$.withScope(RDDOperationScope.scala:150)
at org.apache.spark.rdd.RDDOperationScope$.withScope(RDDOperationScope.scala:111)
at org.apache.spark.rdd.RDD.withScope(RDD.scala:316)
at org.apache.spark.rdd.RDD.map(RDD.scala:323)
at org.apache.spark.api.java.JavaRDDLike$class.map(JavaRDDLike.scala:96)
at org.apache.spark.api.java.AbstractJavaRDDLike.map(JavaRDDLike.scala:46)
at org.mystudy.testcase.TestCase4Sol1.proc3(TestCase4Sol1.java:30)
at org.mystudy.testcase.TestCase4Sol1.main(TestCase4Sol1.java:19)
Caused by: java.io.NotSerializableException: org.mystudy.testcase.TestCase4Sol1
Serialization stack:
- object not serializable (class: org.mystudy.testcase.TestCase4Sol1, value: org.mystudy.testcase.TestCase4Sol1@5e91993f)
- field (class: org.mystudy.testcase.TestCase4Sol1$AAA, name: this$0, type: class org.mystudy.testcase.TestCase4Sol1)
- object (class org.mystudy.testcase.TestCase4Sol1$AAA, org.mystudy.testcase.TestCase4Sol1$AAA@598260a6)
- field (class: org.apache.spark.api.java.JavaPairRDD$$anonfun$toScalaFunction$1, name: fun$1, type: interface org.apache.spark.api.java.function.Function)
- object (class org.apache.spark.api.java.JavaPairRDD$$anonfun$toScalaFunction$1, <function1>)
at org.apache.spark.serializer.SerializationDebugger$.improveException(SerializationDebugger.scala:40)
at org.apache.spark.serializer.JavaSerializationStream.writeObject(JavaSerializer.scala:47)
at org.apache.spark.serializer.JavaSerializerInstance.serialize(JavaSerializer.scala:101)
at org.apache.spark.util.ClosureCleaner$.ensureSerializable(ClosureCleaner.scala:301)
... 13 more
4-2 외부클래스를 이용해서 해결
package org.mystudy.testcase.vo;
import org.apache.spark.api.java.function.Function;
public class AAA implements Function<Integer, Integer> {
@Override
public Integer call(Integer v1) throws Exception {
return v1 + 1;
}
}
package org.mystudy.testcase;
import java.util.Arrays;
import org.apache.log4j.PropertyConfigurator;
import org.apache.spark.api.java.JavaRDD;
import org.apache.spark.api.java.JavaSparkContext;
import org.mystudy.testcase.vo.AAA;
public class TestCase4Sol2 {
private TestCase4Sol2() {
PropertyConfigurator.configure("D:\\workspace\\spark\\learning.spark\\src\\resources\\log4j.properties");
}
public static void main(String... strings) {
TestCase4Sol2 t = new TestCase4Sol2();
t.proc3();
}
private void proc3() {
JavaSparkContext sc = new JavaSparkContext("local[2]", "First Spark App");
JavaRDD rdd2 = sc.parallelize(Arrays.asList(1, 2, 3, 4));
JavaRDD rdd3 = rdd2.map(new AAA()); //해결
System.out.println(rdd3.collect());
}
}
외부 public 클래스를 이용했더니 해결되었다. AAA 클래스가 다른 클래스의 영향을 받지 않고, 순수하게 Function의 영향만 받아서, 문제가 생기지 않는가 보다.
5. 실패사례 - 익명 내부 클래스
package org.mystudy.testcase;
import java.util.Arrays;
import org.apache.log4j.PropertyConfigurator;
import org.apache.spark.api.java.JavaRDD;
import org.apache.spark.api.java.JavaSparkContext;
import org.apache.spark.api.java.function.Function;
public class TestCase5 {
private TestCase5() {
PropertyConfigurator.configure("D:\\workspace\\spark\\learning.spark\\src\\resources\\log4j.properties");
}
public static void main(String... strings) {
TestCase5 t = new TestCase5();
System.out.println("t:"+t);
t.proc3();
}
private void proc3() {
JavaSparkContext sc = new JavaSparkContext("local[2]", "First Spark App");
JavaRDD rdd2 = sc.parallelize(Arrays.asList(1, 2, 3, 4));
JavaRDD rdd3 = rdd2.map(new Function() { // Exception
@Override
public Integer call(Integer v1) throws Exception {
return v1 + 1;
}
});
System.out.println(rdd3.collect());
}
}
왜 Exception 이 발생하는가? 책대로 하였는데-_-'''
책에서 익명 내부 클래스를 사용하라고 했는데;;;
여전히 TestCase5 를 걸고 넘어지고 있다. 그저... Serializable해주면 된다. 그런데 왜 그래야 하는가? 익명인데-___-:;;
아래의 파란색 표시를 보면, 익명이더라도... 참조가 TestCase5 로 되어있다-_-;;;;
t:org.mystudy.testcase.TestCase5@5e91993f
16/04/08 00:40:20 WARN NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
Exception in thread "main" org.apache.spark.SparkException: Task not serializable
at org.apache.spark.util.ClosureCleaner$.ensureSerializable(ClosureCleaner.scala:304)
at org.apache.spark.util.ClosureCleaner$.org$apache$spark$util$ClosureCleaner$$clean(ClosureCleaner.scala:294)
at org.apache.spark.util.ClosureCleaner$.clean(ClosureCleaner.scala:122)
at org.apache.spark.SparkContext.clean(SparkContext.scala:2055)
at org.apache.spark.rdd.RDD$$anonfun$map$1.apply(RDD.scala:324)
at org.apache.spark.rdd.RDD$$anonfun$map$1.apply(RDD.scala:323)
at org.apache.spark.rdd.RDDOperationScope$.withScope(RDDOperationScope.scala:150)
at org.apache.spark.rdd.RDDOperationScope$.withScope(RDDOperationScope.scala:111)
at org.apache.spark.rdd.RDD.withScope(RDD.scala:316)
at org.apache.spark.rdd.RDD.map(RDD.scala:323)
at org.apache.spark.api.java.JavaRDDLike$class.map(JavaRDDLike.scala:96)
at org.apache.spark.api.java.AbstractJavaRDDLike.map(JavaRDDLike.scala:46)
at org.mystudy.testcase.TestCase5.proc3(TestCase5.java:25)
at org.mystudy.testcase.TestCase5.main(TestCase5.java:19)
Caused by: java.io.NotSerializableException: org.mystudy.testcase.TestCase5
Serialization stack:
- object not serializable (class: org.mystudy.testcase.TestCase5, value: org.mystudy.testcase.TestCase5@5e91993f)
- field (class: org.mystudy.testcase.TestCase5$1, name: this$0, type: class org.mystudy.testcase.TestCase5)
- object (class org.mystudy.testcase.TestCase5$1, org.mystudy.testcase.TestCase5$1@60acd609)
- field (class: org.apache.spark.api.java.JavaPairRDD$$anonfun$toScalaFunction$1, name: fun$1, type: interface org.apache.spark.api.java.function.Function)
- object (class org.apache.spark.api.java.JavaPairRDD$$anonfun$toScalaFunction$1, <function1>)
at org.apache.spark.serializer.SerializationDebugger$.improveException(SerializationDebugger.scala:40)
at org.apache.spark.serializer.JavaSerializationStream.writeObject(JavaSerializer.scala:47)
at org.apache.spark.serializer.JavaSerializerInstance.serialize(JavaSerializer.scala:101)
at org.apache.spark.util.ClosureCleaner$.ensureSerializable(ClosureCleaner.scala:301)
... 13 more
5.1 변수로 받아볼까? 안돼~
package org.mystudy.testcase;
import java.util.Arrays;
import org.apache.log4j.PropertyConfigurator;
import org.apache.spark.api.java.JavaRDD;
import org.apache.spark.api.java.JavaSparkContext;
import org.apache.spark.api.java.function.Function;
public class TestCase5Sol1 {
private TestCase5Sol1() {
PropertyConfigurator.configure("D:\\workspace\\spark\\learning.spark\\src\\resources\\log4j.properties");
}
public static void main(String... strings) {
TestCase5Sol1 t = new TestCase5Sol1();
System.out.println("t:"+t);
t.proc3();
}
private void proc3() {
JavaSparkContext sc = new JavaSparkContext("local[2]", "First Spark App");
JavaRDD<Integer> rdd2 = sc.parallelize(Arrays.asList(1, 2, 3, 4));
Function<Integer, Integer> f = new Function<Integer, Integer>() {
@Override
public Integer call(Integer v1) throws Exception {
return v1 + 1;
}
};
System.out.println("f:"+f);
JavaRDD<Integer> rdd3 = rdd2.map(f); //Exception
System.out.println(rdd3.collect());
}
}
변수로 받아보아도 안된다.
에러메시지를 보면 여전히 바깥클래스가 걸려있다.
t:org.mystudy.testcase.TestCase5Sol1@5e91993f
16/04/08 00:44:22 WARN NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
f:org.mystudy.testcase.TestCase5Sol1$1@363f0ba0
Exception in thread "main" org.apache.spark.SparkException: Task not serializable
at org.apache.spark.util.ClosureCleaner$.ensureSerializable(ClosureCleaner.scala:304)
at org.apache.spark.util.ClosureCleaner$.org$apache$spark$util$ClosureCleaner$$clean(ClosureCleaner.scala:294)
at org.apache.spark.util.ClosureCleaner$.clean(ClosureCleaner.scala:122)
at org.apache.spark.SparkContext.clean(SparkContext.scala:2055)
at org.apache.spark.rdd.RDD$$anonfun$map$1.apply(RDD.scala:324)
at org.apache.spark.rdd.RDD$$anonfun$map$1.apply(RDD.scala:323)
at org.apache.spark.rdd.RDDOperationScope$.withScope(RDDOperationScope.scala:150)
at org.apache.spark.rdd.RDDOperationScope$.withScope(RDDOperationScope.scala:111)
at org.apache.spark.rdd.RDD.withScope(RDD.scala:316)
at org.apache.spark.rdd.RDD.map(RDD.scala:323)
at org.apache.spark.api.java.JavaRDDLike$class.map(JavaRDDLike.scala:96)
at org.apache.spark.api.java.AbstractJavaRDDLike.map(JavaRDDLike.scala:46)
at org.mystudy.testcase.TestCase5Sol1.proc3(TestCase5Sol1.java:32)
at org.mystudy.testcase.TestCase5Sol1.main(TestCase5Sol1.java:19)
Caused by: java.io.NotSerializableException: org.mystudy.testcase.TestCase5Sol1
Serialization stack:
- object not serializable (class: org.mystudy.testcase.TestCase5Sol1, value: org.mystudy.testcase.TestCase5Sol1@5e91993f)
- field (class: org.mystudy.testcase.TestCase5Sol1$1, name: this$0, type: class org.mystudy.testcase.TestCase5Sol1)
- object (class org.mystudy.testcase.TestCase5Sol1$1, org.mystudy.testcase.TestCase5Sol1$1@363f0ba0)
- field (class: org.apache.spark.api.java.JavaPairRDD$$anonfun$toScalaFunction$1, name: fun$1, type: interface org.apache.spark.api.java.function.Function)
- object (class org.apache.spark.api.java.JavaPairRDD$$anonfun$toScalaFunction$1, <function1>)
at org.apache.spark.serializer.SerializationDebugger$.improveException(SerializationDebugger.scala:40)
at org.apache.spark.serializer.JavaSerializationStream.writeObject(JavaSerializer.scala:47)
at org.apache.spark.serializer.JavaSerializerInstance.serialize(JavaSerializer.scala:101)
at org.apache.spark.util.ClosureCleaner$.ensureSerializable(ClosureCleaner.scala:301)
... 13 more
5-2. 역시나 Serializable
package org.mystudy.testcase;
import java.io.Serializable;
import java.util.Arrays;
import org.apache.log4j.PropertyConfigurator;
import org.apache.spark.api.java.JavaRDD;
import org.apache.spark.api.java.JavaSparkContext;
import org.apache.spark.api.java.function.Function;
public class TestCase5Sol2 implements Serializable {
private TestCase5Sol2() {
PropertyConfigurator.configure("D:\\workspace\\spark\\learning.spark\\src\\resources\\log4j.properties");
}
public static void main(String... strings) {
TestCase5Sol2 t = new TestCase5Sol2();
t.proc3();
}
public void proc3() {
JavaSparkContext sc = new JavaSparkContext("local[2]", "First Spark App");
JavaRDD<Integer> rdd2 = sc.parallelize(Arrays.asList(1, 2, 3, 4));
Function<Integer, Integer> f = new Function<Integer, Integer>() {
@Override
public Integer call(Integer v1) throws Exception {
return v1 + 1;
}
};
JavaRDD<Integer> rdd3 = rdd2.map(f); // 해결
System.out.println(rdd3.collect());
}
}
그냥.. 쉽게 생각하면, Serializable 해주면 된다-_-;;
클래스에 Serializable 해줄때, 주의할 사항은.. 클래스의 멤버필드가 모두 Serializable 하는데 문제가 없어야 된다.
>>>>
Serializable이 싫다면,,,
JAVA8 의 람다식을 사용하자.
또는 완전 독립적인 클래스(Serializable이 구현된)를 사용하자.
조금 더 해보자...
6.성공케이스 - 외부 클래스의 함수
package org.mystudy.testcase.vo;
public class BBB {
public int add(int num) {
return num + 1;
}
public static int bbb(int num) {
return num + 1;
}
}
package org.mystudy.testcase;
import java.util.Arrays;
import org.apache.log4j.PropertyConfigurator;
import org.apache.spark.api.java.JavaRDD;
import org.apache.spark.api.java.JavaSparkContext;
import org.mystudy.testcase.vo.BBB;
public class TestCase6 {
private TestCase6() {
PropertyConfigurator.configure("D:\\workspace\\spark\\learning.spark\\src\\resources\\log4j.properties");
}
public static void main(String... strings) {
TestCase6 t = new TestCase6();
t.proc3();
}
private void proc3() {
JavaSparkContext sc = new JavaSparkContext("local[2]", "First Spark App");
JavaRDD rdd2 = sc.parallelize(Arrays.asList(1, 2, 3, 4));
JavaRDD rdd3 = rdd2.map(a -> new BBB().add(a)); //성공
System.out.println(rdd3.collect());
}
}
왜 성공인지 모르겠다.-_- BBB 클래스는 Serializable 하지 않았는데...
일단, 위 2~5 사례는 rdd2.map(함수인스턴스 자체); 형태였는데..
지금의 사례는 rdd2.map(a -> 함수연산?); 이라...조금 다르다.
package org.mystudy.testcase;
import java.util.Arrays;
import org.apache.log4j.PropertyConfigurator;
import org.apache.spark.api.java.JavaRDD;
import org.apache.spark.api.java.JavaSparkContext;
import org.mystudy.testcase.vo.BBB;
public class TestCase7 {
private TestCase7() {
PropertyConfigurator.configure("D:\\workspace\\spark\\learning.spark\\src\\resources\\log4j.properties");
}
public static void main(String... strings) {
TestCase7 t = new TestCase7();
t.proc3();
}
private void proc3() {
JavaSparkContext sc = new JavaSparkContext("local[2]", "First Spark App");
JavaRDD rdd2 = sc.parallelize(Arrays.asList(1, 2, 3, 4));
JavaRDD rdd3 = rdd2.map(a -> BBB.bbb(a)); //성공
System.out.println(rdd3.collect());
}
}
static 함수도 잘 된다..왜????
7.실패... 밖으로 나와서 인스턴스를 만들었더니...-__-;;;
package org.mystudy.testcase;
import java.util.Arrays;
import org.apache.log4j.PropertyConfigurator;
import org.apache.spark.api.java.JavaRDD;
import org.apache.spark.api.java.JavaSparkContext;
import org.mystudy.testcase.vo.BBB;
public class TestCase8 {
private TestCase8() {
PropertyConfigurator.configure("D:\\workspace\\spark\\learning.spark\\src\\resources\\log4j.properties");
}
public static void main(String... strings) {
TestCase8 t = new TestCase8();
System.out.println("t:"+t);
t.proc3();
}
private void proc3() {
JavaSparkContext sc = new JavaSparkContext("local[2]", "First Spark App");
JavaRDD rdd2 = sc.parallelize(Arrays.asList(1, 2, 3, 4));
BBB b = new BBB();
System.out.println("b:"+b);
JavaRDD rdd3 = rdd2.map(a -> b.add(a)); //Exception
System.out.println(rdd3.collect());
}
}
위의 잘되던 케이스에서...
람다 밖에서 BBB 인스턴스를 만들어서 넣어줬더니...
이제와서 BBB의 Serializable을 요구한다-_-;;
BBB 클래스에
public class BBB implements Serializable{ 와 같이 구현하면 에러가 사라진다...
이게 뭔가-_-;;;
t:org.mystudy.testcase.TestCase8@75a1cd57
16/04/08 01:09:34 WARN NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
b:org.mystudy.testcase.vo.BBB@681adc8f
Exception in thread "main" org.apache.spark.SparkException: Task not serializable
at org.apache.spark.util.ClosureCleaner$.ensureSerializable(ClosureCleaner.scala:304)
at org.apache.spark.util.ClosureCleaner$.org$apache$spark$util$ClosureCleaner$$clean(ClosureCleaner.scala:294)
at org.apache.spark.util.ClosureCleaner$.clean(ClosureCleaner.scala:122)
at org.apache.spark.SparkContext.clean(SparkContext.scala:2055)
at org.apache.spark.rdd.RDD$$anonfun$map$1.apply(RDD.scala:324)
at org.apache.spark.rdd.RDD$$anonfun$map$1.apply(RDD.scala:323)
at org.apache.spark.rdd.RDDOperationScope$.withScope(RDDOperationScope.scala:150)
at org.apache.spark.rdd.RDDOperationScope$.withScope(RDDOperationScope.scala:111)
at org.apache.spark.rdd.RDD.withScope(RDD.scala:316)
at org.apache.spark.rdd.RDD.map(RDD.scala:323)
at org.apache.spark.api.java.JavaRDDLike$class.map(JavaRDDLike.scala:96)
at org.apache.spark.api.java.AbstractJavaRDDLike.map(JavaRDDLike.scala:46)
at org.mystudy.testcase.TestCase8.proc3(TestCase8.java:27)
at org.mystudy.testcase.TestCase8.main(TestCase8.java:19)
Caused by: java.io.NotSerializableException: org.mystudy.testcase.vo.BBB
Serialization stack:
- object not serializable (class: org.mystudy.testcase.vo.BBB, value: org.mystudy.testcase.vo.BBB@681adc8f)
- element of array (index: 0)
- array (class [Ljava.lang.Object;, size 1)
- field (class: java.lang.invoke.SerializedLambda, name: capturedArgs, type: class [Ljava.lang.Object;)
- object (class java.lang.invoke.SerializedLambda, SerializedLambda[capturingClass=class org.mystudy.testcase.TestCase8, functionalInterfaceMethod=org/apache/spark/api/java/function/Function.call:(Ljava/lang/Object;)Ljava/lang/Object;, implementation=invokeStatic org/mystudy/testcase/TestCase8.lambda$0:(Lorg/mystudy/testcase/vo/BBB;Ljava/lang/Integer;)Ljava/lang/Integer;, instantiatedMethodType=(Ljava/lang/Integer;)Ljava/lang/Integer;, numCaptured=1])
- writeReplace data (class: java.lang.invoke.SerializedLambda)
- object (class org.mystudy.testcase.TestCase8$$Lambda$4/1018067851, org.mystudy.testcase.TestCase8$$Lambda$4/1018067851@5e8c34a0)
- field (class: org.apache.spark.api.java.JavaPairRDD$$anonfun$toScalaFunction$1, name: fun$1, type: interface org.apache.spark.api.java.function.Function)
- object (class org.apache.spark.api.java.JavaPairRDD$$anonfun$toScalaFunction$1, <function1>)
at org.apache.spark.serializer.SerializationDebugger$.improveException(SerializationDebugger.scala:40)
at org.apache.spark.serializer.JavaSerializationStream.writeObject(JavaSerializer.scala:47)
at org.apache.spark.serializer.JavaSerializerInstance.serialize(JavaSerializer.scala:101)
at org.apache.spark.util.ClosureCleaner$.ensureSerializable(ClosureCleaner.scala:301)
... 13 more
'Spark > 러닝 스파크' 카테고리의 다른 글
| Spark 시작하기11 - [러닝 스파크] 3장 RDD로 프로그래밍하기2 (0) | 2016.04.19 |
|---|---|
| Spark 시작하기10 - 알 수 없는 이클립스 강제종료 (0) | 2016.04.19 |
| Spark 시작하기09 - 메모리 Exception (0) | 2016.04.19 |
| Spark 시작하기08 - [러닝 스파크] 3장 RDD로 프로그래밍하기 (0) | 2016.04.16 |
| Spark 시작하기06 - [러닝스파크] 로 전환 (0) | 2016.04.04 |